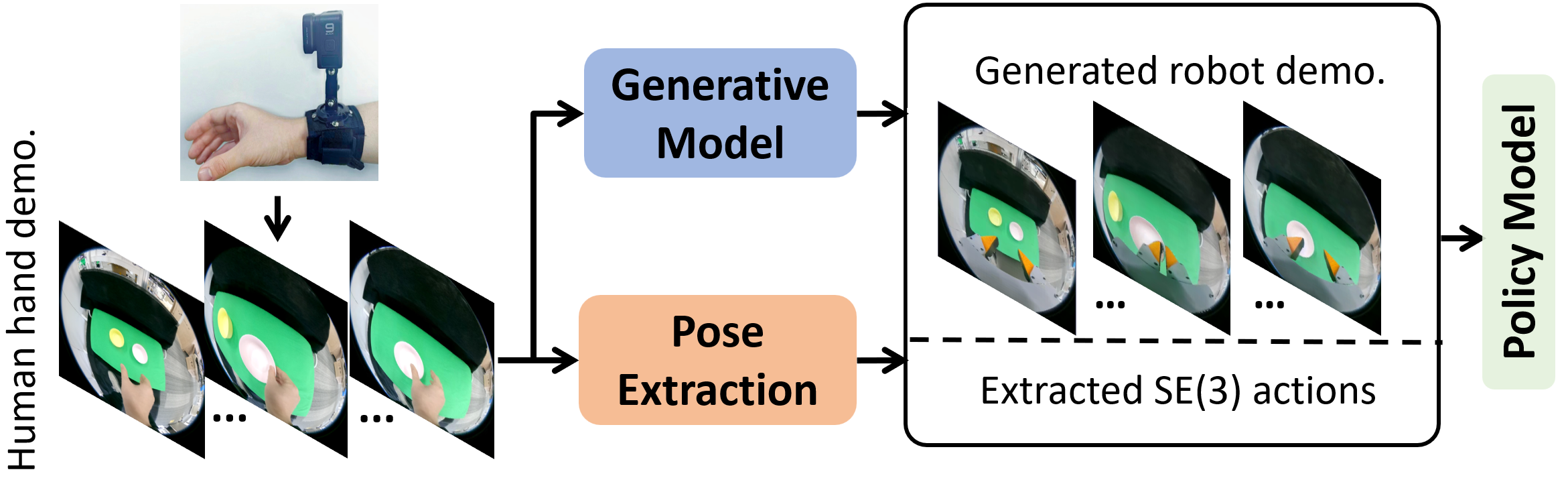
During real robot deployment, our method is evaluated across 9 tasks on the Franka Research 3 (FR3) robot with a 3D-printed UMI gripper. We use a Gopro 9 camera to obtain real-world visual observations from the wrist view. For each task, 50 training human hand demonstrations are collected in a specific working space range. We train an agent for each task and evaluate each task in 15 trials within the training working space. The hand demonstrations and Franka execution demos are shown above.
We adopt UMI as our comparison baseline, which utilizes a hand-held gripper to collect robot gripper demonstrations, serving as the upper bound. As shown in Table, our framework achieves a similar success rate compared to UMI, demonstrating that the quality of our generated robot gripper demonstrations is comparable to those collected directly using a hand-held device.
Moreover, we further compare our method with a baseline (the third row in Table), which uses an alternative approach for generating training ground truth. Specifically, we replace our approach of using a generative model to transfer human hand demonstrations to UMI gripper demonstrations with a simple rule-based texture mapping method. In this approach, we remove the hand parts from the human hand demon-stration, inpaint the background, and then apply the UMI gripper pattern to the image. As a result, the model trained using this data experiences a significant performance drop.
We use the generated robot demonstrations to train the policy model and test its success rate, which can reflect the quality of generated robot gripper demonstrations on unseen action types and instances.
For action type generalization, the generative model's training dataset includes actions "slide block", however, we use the trained diffusion-based generative model to generate robot demonstrations for other actions, such as "rotate block" and "unstack block." Even for unseen action tasks, the success rate of the trained policy model remains high.
For instance generalization, we test the trained generative model on unseen instance appearance, which is not included in the entire generative model training dataset. the success rate remains consistent at 0.87 for both the seen instance pouring the "white cup" and the unseen instance pouring the "yellow cup". Additionally, the unseen instance sliding the "white block" experiences only a minor performance drop of 0.04 compared to the seen instance sliding the "red block".